Analisando o core dump de aplicações no Linux
- por Sergio Prado
Uma das maneiras mais eficientes de identificar problemas em aplicações que encerram abruptamente sua execução é através da análise de core dump.
O core dump é um arquivo que contém a imagem da memória de um processo no momento da sua finalização, gerado pelo kernel durante processamento de alguns sinais como SIGQUIT, SIGILL, SIGABRT, SIGFPE e SIGSEGV.
Uma das situações mais comuns de geração do core dump é quando uma aplicação encerra sua execução abruptamente devido a um crash (acesso inválido à memória, divisão por zero, etc).
Com o core dump, podemos utilizar o debugger (GDB) para inspecionar o estado do processo no momento em que ele foi encerrado e identificar a linha de código com problema.
Por exemplo, imagine que ao executar a aplicação nano temos um erro de acesso inválido à memória:
# nano Segmentation fault |
Por padrão, o core dump não será gerado. Para que o arquivo de core seja gerado, precisamos alterar a configuração de limite do tamanho do arquivo de core do processo (RLIMIT_CORE), que por padrão é zero.
Para alterar esta configuração, podemos utilizar o comando ulimit.
# ulimit -c unlimited |
Agora, basta executar novamente a aplicação para que o arquivo de core seja gerado:
# nano Segmentation fault (core dumped) # ls core |
Por padrão, será gerado um arquivo de nome core no mesmo diretório onde a aplicação foi executada. Este comportamento pode ser alterado em /proc/sys/kernel/core_pattern.
Caso o arquivo de core não seja gerado, é importante verificar se o usuário tem permissão de escrita no diretório e se o sistema de arquivos tem espaço suficiente para armazenar o arquivo de core.
Agora é só analisar o core dump, passando o arquivo de core e o executável da aplicação com símbolos de debugging para o GDB (no meu caso estou trabalhando com uma plataforma ARM, então utilizei o GDB do toolchain de compilação cruzada):
$ arm-linux-gdb -c core nano Core was generated by `nano'. Program terminated with signal SIGSEGV, Segmentation fault. #0 0x00019f14 in signal_init () at nano.c:1192 1192 *sig = SIGINT; |
O GDB irá indicar a linha de código que causou o problema (nano.c:1192 no exemplo acima).
Para uma melhor visualização do código-fonte, podemos abrir o GDB no modo TUI:
$ arm-linux-gdb -c core nano -tui |
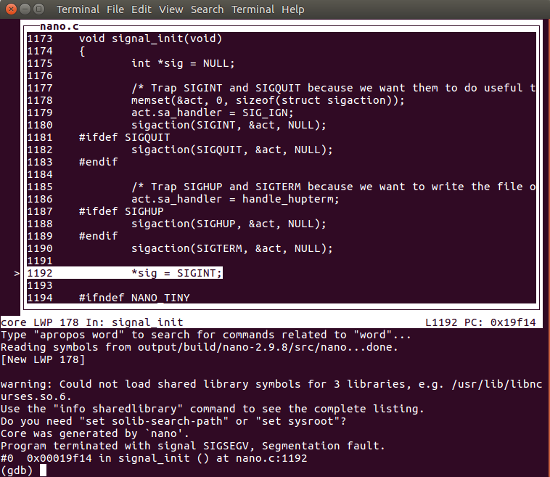
Como o arquivo de core representa o estado da execução da aplicação no momento do crash, podemos inspecionar toda a memória do processo, por exemplo exibindo o conteúdo de variáveis ou o backtrace do stack.
(gdb) bt #0 0x00019f14 in signal_init () at nano.c:1192 #1 0x0001b264 in main (argc=1, argv=0xbee9de64) at nano.c:2568 (gdb) print sig $1 = (int *) 0x0 |
Mais informações sobre a geração e análise de core dump estão disponíveis na página de manual do core.
$ man 5 core |
Happy debugging!
Sergio Prado
