Rastreando o kernel Linux com ftrace
- por Sergio Prado
Tracing é uma técnica bastante útil para encontrar erros em software, e o ftrace é um framework de tracing integrado ao kernel Linux.
Mas antes de estudarmos sobre o ftrace, vamos falar de tracing.
O que é tracing?
Tracing ou rastreamento de código é um log especializado capaz de registrar informações sobre o fluxo de execução de um programa.
Sabe quando você coloca mensagens de debug no código? Você está rastreando o programa com seu próprio “sistema de rastreamento”. As mensagens de debug adicionadas ao código são pontos de rastreamento estáticos e seu “sistema de rastreamento” pode enviar as mensagens de debug para a saída padrão do programa ou para um arquivo de log.
Bom, isso funciona. Mas não escala. Sempre que desejar rastrear parte do programa, você precisará adicionar novas mensagens de debug e recompilar o código. E você não tem muito controle sobre a impressão das mensagens. E se você quiser salvá-las para análise posterior? E se você quiser filtrar as mensagens? E o código ficará uma bagunça, com muitas mensagens de debug. Será necessário ter muito cuidado para não comitar nenhum código com mensagens de debug.
O fato é que na maioria das vezes não precisamos adicionar mensagens de debug no código, porque já existem ferramentas e frameworks de tracing que podem fazer isso automaticamente por nós!
É aí que entra o ftrace…
O que é o ftrace?
O Ftrace é um framework de tracing do kernel Linux. Ele foi adicionado ao kernel em 2008 e evoluiu bastante desde então.
Ftrace significa function tracer e basicamente permite monitorar e registrar o fluxo de execução das funções do kernel. Foi criado por Steven Rostedt, derivado de duas outras ferramentas chamadas latency tracer do Ingo Molnar e logdev do próprio Steven Rostedt.
Com o ftrace, podemos realmente ver o que o kernel está fazendo. Podemos rastrear as chamadas de função e aprender muito sobre como o kernel funciona. Podemos descobrir quais funções do kernel são chamadas quando executamos uma aplicação em espaço de usuário.
Podemos medir o tempo de execução das funções e descobrir gargalos e problemas de desempenho. Podemos identificar travamentos no espaço do kernel. Podemos medir o tempo necessário para executar uma tarefa de tempo real e descobrir problemas de latência. Podemos medir o consumo de pilha em espaço de kernel e descobrir possíveis estouros de pilha. É uma ferramenta extremamente útil para monitorar e encontrar bugs no kernel!
Mas como ele funciona? Magia negra? Talvez um pouco. :-)
Como o ftrace funciona?
Existem dois principais tipos de implementação de tracing: estático e dinâmico.
Tracing estático é implementado através de pontos de rastreamento estáticos adicionados ao código-fonte. Possuem baixa carga de processamento, porém o código rastreado é limitado e definido em tempo de compilação.
Tracing dinâmico é implementado através pontos de rastreamento dinâmicos injetados no código (normalmente através de interrupção de software), permitindo definir em tempo de execução o código a ser rastreado. Possui uma certa carga de processamento, mas a abrangência do código-fonte a ser rastreado é bem maior.
O ftrace utiliza uma combinação de tracing estático (rastreamento de funções, rastreamento de eventos, etc.) e tracing dinâmico (kprobes, uprobes, etc).
Para rastrear as chamadas de função, o ftrace irá compilar o kernel com a opção -pg do GCC.
Quando o kernel é compilado com -pg, serão adicionadas algumas instruções da máquina no início de cada função (que não seja inline) do kernel, redirecionando a execução para os plugins de tracing do ftrace.
A código em Assembly abaixo é o prólogo da função gpiod_set_value do kernel compilado com tracing habilitado. A chamada __ gnu_mcount_nc na linha 10 foi adicionada pelo GCC e será utilizada pelo ftrace para instrumentação (essa é a mesma técnica utilizada pelo gprof para analisar a performance de aplicações em espaço de usuário).
1 2 3 4 5 6 7 8 9 10 11 12 |
$ arm-linux-gdb -q vmlinux
Reading symbols from vmlinux...done.
(gdb) disassemble /m gpiod_set_value
Dump of assembler code for function gpiod_set_value:
3133 {
0xc03a83ac <+0>: mov r12, sp
0xc03a83b0 <+4>: push {r4, r5, r11, r12, lr, pc}
0xc03a83b4 <+8>: sub r11, r12, #4
0xc03a83b8 <+12>: push {lr} ; (str lr, [sp, #-4]!)
0xc03a83bc <+16>: bl 0xc001b420 <__gnu_mcount_nc>
0xc03a83c0 <+20>: mov r5, r1
0xc03a83c8 <+28>: mov r4, r0 |
O Ftrace também é capaz de rastrear eventos (trace events) do kernel.
Trace events são pontos de rastreamento estáticos adicionados pelos desenvolvedores para monitorar os subsistemas do kernel, como o escalonador de tarefas, gerenciamento de energia, tratamento de interrupções, camada de rede, GPIO, etc. Basta procurar por funções começando com trace_ no código-fonte do kernel Linux e você encontrará vários locais onde os trace events são utilizados:
$ grep -R trace_ drivers/gpio/* drivers/gpio/gpiolib.c: trace_gpio_direction(desc_to_gpio(desc), 1, status); drivers/gpio/gpiolib.c: trace_gpio_value(desc_to_gpio(desc), 0, val); drivers/gpio/gpiolib.c: trace_gpio_direction(desc_to_gpio(desc), 0, ret); drivers/gpio/gpiolib.c: trace_gpio_value(desc_to_gpio(desc), 1, value); drivers/gpio/gpiolib.c: trace_gpio_value(desc_to_gpio(desc), 1, value); drivers/gpio/gpiolib.c: trace_gpio_direction(desc_to_gpio(desc), value, err); drivers/gpio/gpiolib.c: trace_gpio_direction(desc_to_gpio(desc), !value, err); drivers/gpio/gpiolib.c: trace_gpio_value(desc_to_gpio(desc), 0, value); drivers/gpio/gpiolib.c: trace_gpio_value(desc_to_gpio(desc), 0, value); |
Mas como interagimos com o ftrace?
Quando o tracing é ativado, todos os dados de rastreamento coletados serão armazenados pelo ftrace em um buffer circular em memória.
Existe um sistema de arquivos virtual chamado tracefs (geralmente montado em /sys/kernel/tracing) para interfacear com o ftrace. Através deste sistema de arquivos, podemos configurar o ftrace e coletar os dados de rastreamento.
O fato da interface ser através de operações em arquivos é uma característica interessante do ftrace, já que é possível utilizar ferramentas simples como echo e cat para rastrear o kernel Linux!
Como então usar o ftrace?
Primeiro devemos habilitar o ftrace no kernel (opção CONFIG_FTRACE), incluindo todas as funcionalidades que planejamos utilizar. Esta é a tela de configuração do kernel versão 4.18 com a maioria das opções do ftrace habilitadas:

Com o ftrace habilitado, podemos montar o sistema de arquivos virtual tracefs:
# mount -t tracefs tracefs /sys/kernel/tracing |
E esta é a interface de arquivos provida pelo ftrace:
# ls /sys/kernel/tracing/ README set_ftrace_filter available_events set_ftrace_notrace available_filter_functions set_ftrace_pid available_tracers set_graph_function buffer_size_kb set_graph_notrace buffer_total_size_kb snapshot current_tracer stack_max_size dyn_ftrace_total_info stack_trace enabled_functions stack_trace_filter events timestamp_mode free_buffer trace function_profile_enabled trace_clock hwlat_detector trace_marker instances trace_marker_raw max_graph_depth trace_options options trace_pipe per_cpu trace_stat printk_formats tracing_cpumask saved_cmdlines tracing_max_latency saved_cmdlines_size tracing_on saved_tgids tracing_thresh set_event uprobe_events set_event_pid uprobe_profile |
Podemos exibir a lista de tracers disponíveis:
# cat available_tracers hwlat blk function_graph wakeup_dl wakeup_rt wakeup irqsoff function nop |
Existem tracers de função (function, function_graph), tracers de latência (wakeup_dl, wakeup_rt, irqsoff, wakeup, hwlat), tracers de I/O (blk), etc.
Para habilitar um tracer, precisamos escrever seu nome no arquivo current_tracer:
# echo function > current_tracer |
Depois podemos ler o buffer de tracing através dos arquivos trace ou trace_pipe:
# cat trace
# tracer: function
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
<idle>-0 [001] d... 23.695208: _raw_spin_lock_irqsave <-hrtimer_next_event_wi...
<idle>-0 [001] d... 23.695209: __hrtimer_next_event_base <-hrtimer_next_event...
<idle>-0 [001] d... 23.695210: __next_base <-__hrtimer_next_event_base
<idle>-0 [001] d... 23.695211: __hrtimer_next_event_base <-hrtimer_next_event...
<idle>-0 [001] d... 23.695212: __next_base <-__hrtimer_next_event_base
<idle>-0 [001] d... 23.695213: __next_base <-__hrtimer_next_event_base
<idle>-0 [001] d... 23.695214: _raw_spin_unlock_irqrestore <-hrtimer_next_eve...
<idle>-0 [001] d... 23.695215: get_iowait_load <-menu_select
<idle>-0 [001] d... 23.695217: tick_nohz_tick_stopped <-menu_select
<idle>-0 [001] d... 23.695218: tick_nohz_idle_stop_tick <-do_idle
<idle>-0 [001] d... 23.695219: rcu_idle_enter <-do_idle
<idle>-0 [001] d... 23.695220: call_cpuidle <-do_idle
<idle>-0 [001] d... 23.695221: cpuidle_enter <-call_cpuidle |
O function_graph é um tracer de funções alternativo que rastreia não apenas a entrada da função, mas também também seu retorno, permitindo criar um gráfico de chamada de função em um estilo parecido com a linguagem C, incluindo informações sobre o tempo de execução de cada função.
# echo function_graph > current_tracer
# cat trace
# tracer: function_graph
#
# CPU DURATION FUNCTION CALLS
# | | | | | | |
0) 1.000 us | } /* idle_cpu */
0) | tick_nohz_irq_exit() {
0) | ktime_get() {
0) 1.000 us | clocksource_mmio_readl_up();
0) 7.666 us | }
0) + 14.000 us | }
0) | rcu_irq_exit() {
0) 1.334 us | rcu_nmi_exit();
0) 7.667 us | }
0) ! 556.000 us | } /* irq_exit */
0) # 1187.667 us | } /* __handle_domain_irq */
0) # 1194.333 us | } /* gic_handle_irq */
0) <========== |
0) # 8197.333 us | } /* cpuidle_enter_state */
0) # 8205.334 us | } /* cpuidle_enter */ |
A quantidade de dados gerados pelo tracing pode ser muito grande, por isso existem diversas opções de filtro no ftrace. Por exemplo, podemos configurar um filtro para rastrear apenas um pequeno grupo de funções do kernel, ou então filtrar por PID e rastrear apenas funções do kernel executadas por um processo específico do sistema.
No exemplo abaixo, estamos rastreando apenas as funções que começam com snvs, correspondentes ao driver de RTC da NXP:
# echo "snvs*" > set_ftrace_filter
# echo function > current_tracer
# cat trace_pipe
Binder_3-836 [000] ...1 5890.663049: snvs_rtc_set_time <-rtc_set_time
Binder_3-836 [000] ...1 5890.663063: snvs_rtc_enable <-snvs_rtc_set_time
Binder_3-836 [000] ...1 5890.663106: snvs_rtc_enable <-snvs_rtc_set_time
kworker/0:0-2128 [000] ...1 5890.663215: snvs_rtc_read_time <-__rtc_read_time |
Podemos também ativar o tracing de eventos específicos do kernel, como escalonamento de tarefas, acesso a GPIOs ou chamadas de sistema. No exemplo abaixo, estamos rastreando apenas eventos de GPIO:
# echo 1 > events/gpio/enable
# cat trace_pipe
mmcqd/2-103 [000] d..2 778.002889: gpio_value: 73 get 0
mmcqd/2-103 [000] d..2 778.002910: gpio_value: 73 get 0
mmcqd/2-103 [000] d..2 778.007575: gpio_value: 73 get 0
mmcqd/2-103 [000] d..2 778.013398: gpio_value: 73 get 0 |
Também podemos utilizar o ftrace para medir latências em espaço de kernel (latência com as interrupções desabilitadas, latência para executar um processo de tempo-real, etc).
É bom poder usar ferramentas simples como cat e echo para rastrear o kernel Linux. Mas, às vezes, precisamos escrever em vários arquivos diferentes para configurar uma sessão de tracing. Nesse caso, a ferramenta trace-cmd pode ajudar.
A ferramenta trace-cmd
trace-cmd é uma ferramenta de linha de comando criada por Steven Rostedt que serve de interface para o ftrace.
É um front-end para o sistema de arquivos tracefs e pode ser usada para configurar o ftrace, ler o buffer de tracing e salvar os dados em um arquivo (trace.dat por padrão) para análise posterior.
# trace-cmd
trace-cmd version 2.6.1
usage:
trace-cmd [COMMAND] ...
commands:
record - record a trace into a trace.dat file
start - start tracing without recording into a file
extract - extract a trace from the kernel
stop - stop the kernel from recording trace data
restart - restart the kernel trace data recording
show - show the contents of the kernel tracing buffer
reset - disable all kernel tracing and clear the trace buffers
report - read out the trace stored in a trace.dat file
stream - Start tracing and read the output directly
profile - Start profiling and read the output directly
hist - show a historgram of the trace.dat information
stat - show the status of the running tracing (ftrace) system
split - parse a trace.dat file into smaller file(s)
options - list the plugin options available for trace-cmd report
listen - listen on a network socket for trace clients
list - list the available events, plugins or options
restore - restore a crashed record
snapshot - take snapshot of running trace
stack - output, enable or disable kernel stack tracing
check-events - parse trace event formats |
Por exemplo, o comando abaixo irá iniciar um tracing de função:
# trace-cmd start -p function |
O comando abaixo irá rastrear os eventos de GPIO:
# trace-cmd start -e gpio |
Podemos também, com um único comando, rastrear um processo específico e armazenar o resultado em um arquivo:
# trace-cmd record -p function -F ls /
plugin 'function'
CPU0 data recorded at offset=0x30d000
737280 bytes in size
CPU1 data recorded at offset=0x3c1000
0 bytes in size
# ls trace.dat
trace.dat |
E depois exibir o resultado do tracing com o comando report:
# trace-cmd report
CPU 1 is empty
cpus=2
ls-175 [000] 43.359618: function: mutex_unlock <-- rb_simple_write
ls-175 [000] 43.359624: function: __fsnotify_parent <-- vfs_write
ls-175 [000] 43.359625: function: fsnotify <-- vfs_write
ls-175 [000] 43.359627: function: __sb_end_write <-- vfs_write |
Ou podemos abrir o arquivo com o KernelShark.
KernelShark
O KernelShark é uma ferramenta gráfica que serve de front-end para o arquivo trace.dat gerado pelo trace-cmd.
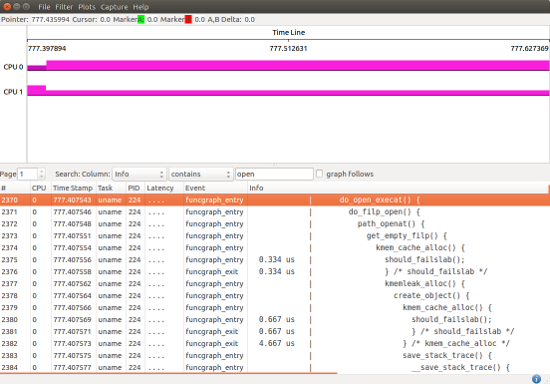
A ferramenta possui duas áreas principais de visualização.
A metade superior é uma exibição gráfica dos dados (por CPU ou tarefa). Você pode aumentar ou diminuir o zoom em um determinado local para ver os detalhes dos eventos em um período específico de tempo.
A metade inferior é uma exibição de lista de eventos de tracing, com opções de filtro para ajudar a analisar os dados de rastreamento.
Mais informações sobre a ferramenta estão disponíveis na documentação do KernelShark.
Estudamos aqui o trace-cmd e o KernelShark, mas muitas outras ferramentas usam o ftrace atualmente, incluindo o perf e implementações de kernel live patching.
Para saber mais, leia a documentação de tracing do kernel e a documentação do ftrace.
Também há palestras muito boas do Steven Rostedt no YouTube, dentre elas Understanding the Linux Kernel via Ftrace, See what your computer is doing with Ftrace utilities, Learning the Linux Kernel with tracing e ftrace: Where modifying a running kernel all started.
Embora este artigo não explore o ftrace em detalhes, ele serve de base para artigos futuros em que explorarei o ftrace para medir latências e identificar diferentes tipos de problemas no kernel Linux.
Happy tracing!
Sergio Prado

Sem Comentários
Nenhum comentário até agora... é a sua chance de ser o primeiro a comentar!